

You must log in or register to comment.
This application looks fine to me.
Clearly labeled sections.
Local on one side, remote on the other
Transfer window on bottom.
No space for anything besides function, is the joke going over my head?
I’m sure there’s nothing wrong with the program at all =)
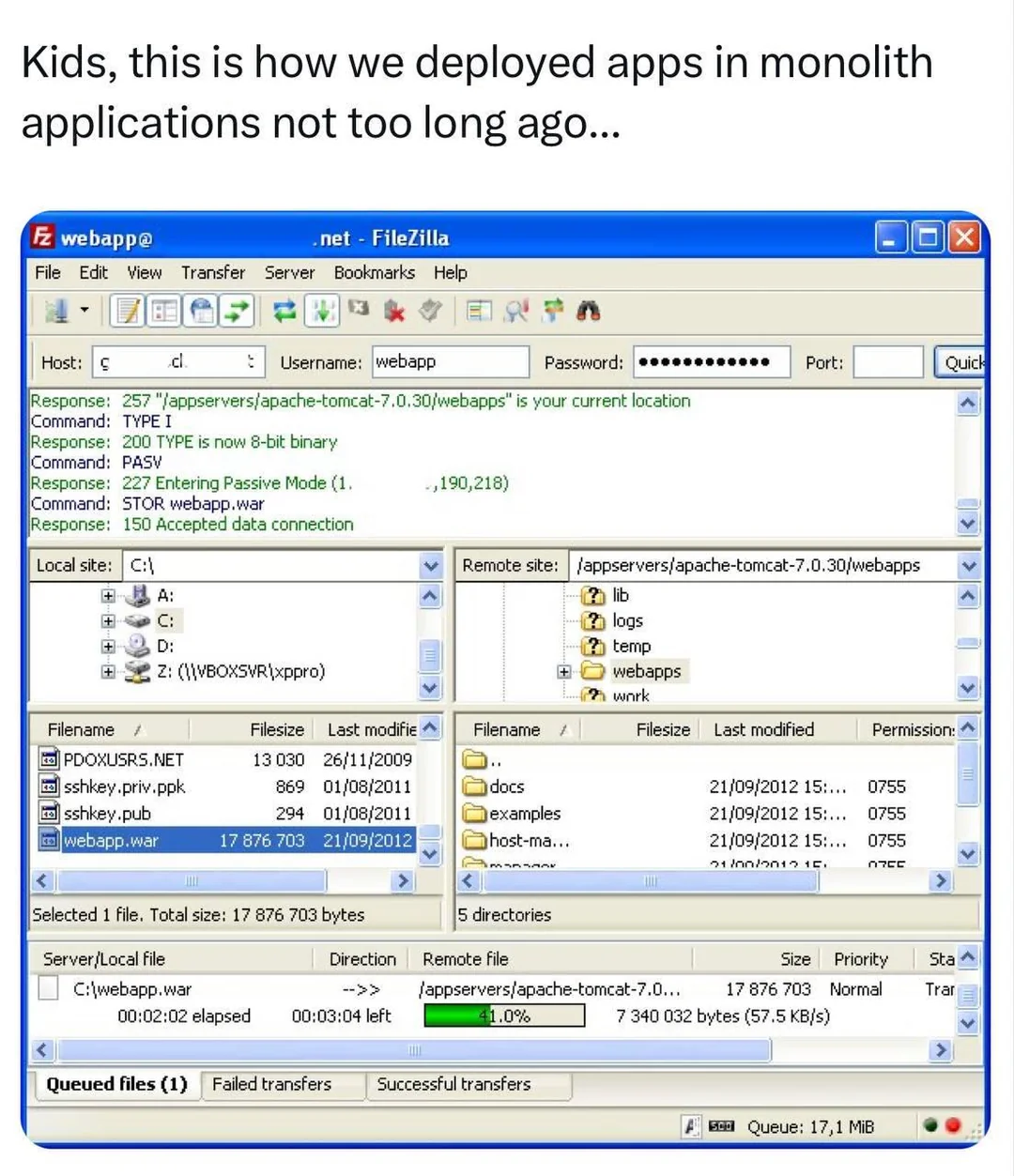
Modern webapp deployment approach is typically to have an automated continuous build and deployment pipeline triggered from source control, which deploys into a staging environment for testing, and then promotes the same precise tested artifacts to production. Probably all in the cloud too.
Compared to that, manually FTPing the files up to the server seems ridiculously antiquated, to the extent that newbies in the biz can’t even believe we ever did it that way. But it’s genuinely what we were all doing not so long ago.
manually FTPing the files up to the server seems ridiculously antiquated
But … but I do that, and I’m only 18 :(
Old soul :)
That’s probably okay! =) There’s some level of pragmatism, depending on the sort of project you’re working on.
If it’s a big app with lots of users, you should use automation because it helps reliability.
If there are lots of developers, you should use automation because it helps keep everyone organised and avoids human mistakes.
But if it’s a small thing with a few devs, or especially a personal project, it might be easier to do without :)
It’s perfectly fine for some private page etc. but when you make business software for customers that require 99,9% uptime with severe contractual penalties it’s probably too wonky.
Think of this like saying using a scythe to mow your lawn is antiquated. If your lawn is tiny then it doesn’t really matter. But we’re talking about massive “enterprise scale” lawns lol. You’re gonna want something you can drive.
Then switch to use sth more like scp ASAP? :-)
Nah, it’s probably more efficient to .tar.xz it and use netcat.
On a more serious note, I use sftp for everything, and git for actual big (but still personal) projects, but then move files and execute scripts manually.
And also, I cloned my old Laptops /dev/sda3 to my new Laptops /dev/main/root (on /dev/mapper/cryptlvm) via netcat over a Gigabit connection with netcat. It worked flawlessly. I love Linux and its Philosophy.
Ooh I’ve never heard of it. netcat I mean, cause I’ve heard of Linux 😆.
The File Transfer Protocol is just very antiquated, while scp is simple. Possibly netcat is too:-).
Netcat is basically just a utility to listen on a socket, or connect to one, and send or receive arbitrary data. And as, in Linux, everything is a file, which means you can handle every part of your system (eg. block devices [physical or virtual disks]) like a normal file, i.e. text, you can just transfer a block device (e.g. /dev/sda3) over raw sockets.
Like anything else, it’s good to know how to do it in many different ways, it may help you down the line.
In production in an oddball environment, I have a python script to ftp transfer to a black box with only ftp exposed as an option.
Another system rebuilds nightly only if code changes, publishing to a QC location. QC gives it a quick review (we are talking website here, QC is “text looks good and nothing looks weird”), clicks a button to approve, and it gets published the following night.
I’ve had hardware (again, black box system) where I was able to leverage git because it was the only command exposed. Aka, the command they forgot to lock down and are using to update their device. Their intent was to sneakernet a thumb drive over to it for updates, I believe in sneaker longevity and wanted to work around that.
So you should know how to navigate your way around in FTP, it’s a good thing! But I’d also recommend learning about all the other ways as well, it can help in the future.
(This comment brought to you by “I now feel older for having written it”, and “I swear I’m only in my fourties,”)
Not to rub it in, but in my forties could be read as almost the entirety of the modern web was developed during my adulthood.
It could, but I’m in my early 40s.
I just started early with a TI-99/4A, then a 286, before building my own p133.
So the “World Wide Web!” posters were there for me in middle school.
Still old lol
Promotes/deploys are just different ways of saying file transfer, which is what we see here.
Nothing was stopping people from doing cicd in the old days.
Sure, but having a hands-off pipeline for it which runs automatically is where the value is at.
Means that there’s predictability and control in what is being done, and once the pipeline is built it’s as easy as a single button press to release.
How many times when doing it manually have you been like “Oh shit, I just FTPd the WRONG STUFF up to production!” - I know I have. Or even worse you do that and don’t notice you did it.
Automation takes a lot of the risk out.
Not to mention the benefits of versioning and being able to rollback! There’s something so satisfying about a well set-up CI/CD pipeline.
We did versioning back in the day too. $application copied to $application.old
But was $application.old_final the one to rollback to, or $application.old-final2?!
deleted by creator
Yes, exactly that.
But it’s genuinely what we were all doing not so long ago
Jokes on you, my first job was editing files directly in production. It was for a webapp written in Classic ASP. To add a new feature, you made a copy of the current version of the page (eg
index2_new.aspbecameindex2_new_v2.asp) and developed your feature there by hitting the live page with your web browser.When you were ready to deploy, you modified all the other pages to link to your new page
Good times!
webapp deployment
Huh? Isn’t this something that runs on the server?
It’s good practice to run the deployment pipeline on a different server from the application host(s) so that the deployment instances can be kept private, unlike the public app hosts, and therefore can be better protected from external bad actors. It is also good practice because this separation of concerns means the deployment pipeline survives even if the app servers need to be torn down and reprovisioned.
Of course you will need some kind of agent running on the app servers to be able to receive the files, but that might be as simple as an SSH session for file transfer.
Shitty companies did it like that back then - and shitty companies still don’t properly utilize what easy tools they have available for controlled deployment nowayads. So nothing really changed, just that the amount of people (and with that, amount of morons) skyrocketed.
I had automated builds out of CVS with deployment to staging, and option to deploy to production after tests over 15 years ago.
after tests
What is “tests”?
Tests is the industry name for the automated paging when production breaks
This application looks fine to me.
Clearly labeled sections.
Local on one side, remote on the other
Transfer window on bottom
Thats how you know its old. Its not caked full of ads, insanely locked down, and trying yo sell you a subscription service.
Except that FileZilla does come with bundled adware from their sponsors and they do want you to pay for the pro version. It probably is the shittiest GPL-licensed piece of software I can think of.
https://en.wikipedia.org/wiki/FileZilla#Bundled_adware_issues
Aw that sucks
deleted by creator
It even has questionably-helpful mysterious blinky lights at the bottom right which may or may not do anything useful.
The joke isn’t the program itself, it’s the process of deploying a website to servers.
The large .war (Web ARchive) being uploaded monolithicly is the archaic deployment of a web app. Modern tools can be much better.
Of course, it’s going to be difficult to find a modern application where each individually deployed component isn’t at least 7MB of compiled source (and 50-200MB of container), compared to this single 7MB
warthat contained everything.And then confused screaming about all the security holes.
Some of us still do 🙃
If it ain’t broke, don’t fix it.
deleted by creator
Anybody that actually professionally deals with this kind of thing understands just how wrong you are.
I remember joining the industry and switching our company over to full Continuous Integration and Deployment. Instead of uploading DLL’s directly to prod via FTP, we could verify each build, deploy to each environment, run some service tests to see if pages were loading, all the way up to prod - with rollback. I showed my manager, and he shrugged. He didn’t see the benefit of this happening when, in his eyes, all he needed to do was drag and drop, and load the page to make sure all is fine.
Unsurprisingly, I found out that this is how he builds websites to this day…
People don’t use FileZilla for server management anymore? I feel like I’ve missed that memo.
I suppose in the days of ‘Cloud Hosting’ a lot of people (hopefully) don’t just randomly upload new files (manually) on a server anymore.
Even if you still just use normal servers that behave like this, a better practice would be to have a build server that creates builds, like whenever you check code into the Main branch, it’ll create a deploy for the server, and you deploy it from there - instead of compiling locally, opening filezilla and doing an upload.
If you’re using ‘Cloud Hosting’ - for example AWS - If you use VMs or bare metal - you’d maybe create Elastic Beanstalk images and upload a new Application or Machine Image as a new version, and deploy that in a more managed way. Or if you’re using Docker, you just upload a new Docker image into a Docker registry and deploy those.
For some of my sites, I still build on my PC and rsync the build directory across. I’ve been meaning to set up Gitlab or something similar and configure automated deployments.
This is what I do because my sites aren’t complicated enough to warrant a build system. Personally I think most websites out there are over-engineered. Example: a Discord friend made a React site that displays stats from a gaming server. It looks nice, but you literally can’t hyperlink to any of the data, it can only be loaded dynamically and only looks coherent on a phone in portrait mode. There are a lot of people following trends (some good trends) but without really thinking about why.
I’m starting to like the htmx model a lot. Server-rendered app that uses HTML attributes to configure the dynamic bits (e.g. which URL to hit and which DOM element to insert the response into). Don’t have to write much JS (or any in some cases).
you literally can’t hyperlink to any of the data
I thought most React-powered frameworks use a URL router out-of-the-box these days? The developer does need to have a rough idea what they’re doing, though.
Yea, I wasn’t saying it’s always bad in every scenario - but we used to have this kinda deployment in a professional company. It’s pretty bad if this is still how you’re doing it like this in an enterprise scenarios.
But for a personal project, it’s alrightish. But yea, there are easier setups. For example configuring an automated deployed from Github/Gitlab. You can check out other peoples’ deployment config, since all that stuff is part of the repos, in the
.githubfolder. So probably all you have to do is find a project that’s similar to yours, like “static file upload for an sftp” - and copypaste the script to your own repo.(for example: a script that publishes a website to github pages)
They have bundled malware from the main downloads on their own site multiple times over the years, and even denied it and tried gaslighting people that AVs were giving false positives because AV companies are paid off by other corporations. And the admin will even try to delete the threads about this stuff but web archive to the rescue…
You know what? I didn’t believe you, since I’m using it for a long time on Linux and never had any issues with it. Today, when I helped a friend (on Windows) with some SFTP transfer and recommended FileZilla was the first time I realised the official Downloads page provides Adware. The executable even gets flagged by Microsoft Defender and VirusTotal. That’s actually REALLY bad. Isn’t FileZilla operated by Mozilla? Should I stop using it, even though the Linux versions don’t have sketchy stuff? It definitely leaves a really bad taste.
Yeah, it’s bad. Surprised they’re still serving that crap in their own bundle but i guess some things don’t change.
Filezilla is no relation to mozilla. But yeah i moved away from it years ago. The general recommendation I’ve seen is “anything but filezilla”. Personally i use winscp for windows, and will have to figure out what to use when i switch my daily driver to Linux.
FileZilla isn’t even that old school, cuteftp was the OG one afaik.
No way, WS_FTP was more OG.
Oh god, I know all of these.
Also fuck Tim Kosse. Bundled Filezilla with malware and fucked up my machine in 2014. Had to reinstall Windows. I’ll never use it again.
I use WinSCP on Windows and Forklift on MacOS.
Yeah you’re totally right, I forgot about that.
There was flashfxp too but I think that was a fair bit later. Revolutionized being a warez courier.
I’m not FBI
being a warez courier.
Spill. You bring those R5s across the ocean? Send audio from the handicap audio jack at the multiplex? Hustle up some telecines? Sneak Battletoads outta the backroom at GameStop before it hit shelves?
Back in the day (mid/late 90’s), there were private ftp servers that required a ratio. Some of these were run by release groups and hard to get on, some were more public. Couriers would download from one site and upload to another to build their ratio and get access to the good sites.
Before people figured out you could connect two ftp servers together directly, you would have to download to your computer and reupload. Most people were on dialup, so that was a non trivial time commitment.
Ohhh didn’t know about that sense of the word in that context. Interesting!
Do you have any idea what the warez scene is like today?
Also there was a bot on the former Warez-BB dot org that would post scene releases seemingly moments after they pre’d. Imagine those kinds of people are on Telegram or something today…
Nope, no idea what it’s like today.
The joys of having $xx/mo to reward creators. (Maybe only $.xx goes to the actual creators but still, it feels better!)
I remember WS_FTP LE leaving log files everywhere. What a pain to clean up.
Yeah, I used to use filezilla and I’m not that old… Right? …Right?
Sure, grandpa/grandma, time for your medicine.
I mean, a lot of docker files out there with
COPY . .True, but building the image is not the same as deploying to production.
Fair point
Somehow I miss those days. Now you need weeks of training to understand the black magic behind all the build/deployment stuff in whatever cloud provider your company decided to use…
We got our own platform based on kubernetes and cncf stuff and we don’t have to care anymore about the metal underneath. AWS? OTC? Azure? Thats just a target parameter, platform does the rest. It’s great.
How often do you switch cloud providers that this is even a real rather than a hypothetical benefit? (Compared to the cost of dealing with a much more complicated stack.)
It’s not about switching, it’s about hosting our services on different platforms at the same time.
I manage a stack like this, we have dedicated hardware running a steady state of backend processing, but scale into AWS if there’s a surge in realtime processing needed and we don’t have the hardware. We also had an outage in our on prem datacenter once which was expensive for us (I assume an insurance claim was made), but scaling to AWS was almost automatic, and the impact was minimal for a full datacenter outage.
If we wanted to optimize even more, I’m sure we could scale into Azure depending on server costs when spot pricing is higher in AWS. The moral of the story is to not get too locked into any one provider and utilize some of the abstraction layers so that AWS, Azure, etc are just targets that you can shop around for by default, without having to scramble.
Naa, once you figure out one the rest click usually.
I remember this. I also remember using
scpinstead. Andftp, if I go back far enough.rsyncis still my friend thoughzfshas mostly replaced it now.How has zfs replaced rsync for you? One is a filesystem, and the other is a filesyncing tool. Does zfs do something im not aware of lol?
I used to use
rsyncto copy data from my storage array on one machine to an external and an off site backup. Since a lot of it was code, it always took forever to scan all the small files, and I had to script unlocking remote partitions.With encrypted ZFS, I can just
zfs snapthenzfs send, and it does the same thing at the block level, raw, so way faster, less data transfer, and no need to send a key or passphrase unless I need to mount it at the destination (meaning a cloud provider could never know the data, for instance).ZFS is also recursive, so if I have
s/storageand/storage/stuffdefined, I can snap and send either level, which makes it as versatile as rsync.Oh interesting, i am not super familar with zfs’ tools, so thats pretty cool! Ill have to look at that for my storage array.
rsyncgang when?The year Linux takes over the desktops!
I fell like the reason nobody uses FileZila and etc anymore is because everybody that wanted it migrated to Linux already. So seriously, it already happened.
FTP and rsync my beloved
I never liked FileZilla. I used Cyberduck
There’s just so few decent FTP clients out there, and all of them are very ugly lol
FTP isn’t really used much any more. SFTP (file transfers over SSH) mostly took over, and people that want to sync a whole directory to the server usually use rsync these days.
Why make bugs with a better UI?
Why not make a better UI after ironing out the bugs?
Why make a better UI when it’ll probably introduce a slew of new bugs?
Isn’t Cyberduck a paid program though? I remember trying it, but I can’t remember why I went back to filezilla. I thought it was because my trial for Cyberduck expired.
Not when I used it like 10 years ago. Not sure about now
A lot are still doing that and haven’t moved up
(Please at least use SFTP!)
okay, but why did you use a password when the ssh/sftp key is right next to the files
I used CuteFTP, but I am a gentleman
“Felt cute, might transfer files later, idk”
This is how I deployed web servers in school like 3 years ago.
My school had nothing about react, node, angular, angularJS, SaaS, etc. back in 2015.
We learned Perl, PHP, LAMP stack, SOAP based APIs and other “antiquated” things. Provided a solid foundation of fundamentals that I’ve built a nice career on.
It might have been by design to get a feel for the fundamentals. Or maybe it’s just because the people teaching it have probably left the industry and are teaching how they did it.
My department head was in his 70s and my professors all trended on the older side.
Same here. But maybe that’s why i recognize a software stack in the GB as a security risk.
Yeah it’s not all that uncommon in school, just increasingly uncommon in industry.
















{kind=link}