Attached: 2 images
Today I learned that YouTube is deliberately crippling Firefox on Asahi Linux. It will give you lowered video resolutions. If you just replace "aarch64" with "x86_64" in the UA, suddenly you get 4K and everything.
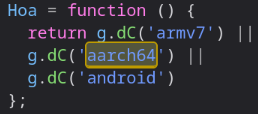
They literally have a test for "is ARM", and if so, they consider your system has garbage performance and cripple the available formats/codecs. I checked the code.
Logic: Quality 1080 by default. If your machine has 2 or fewer cores, quality 480. If anything ARM, quality 240. Yes, Google thinks all ARM machines are 5 times worse than Intel machines, even if you have 20 cores or something.
Why does this not affect Chromium? **Because chromium on aarch64 pretends to be x86_64**
`Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36`
🤦♂️🤦♂️🤦♂️🤦♂️🤦♂️
Welp, guess I'm shipping a user agent override for Firefox on Fedora to pretend to be x86.
**EDIT**: The plot thickens. Pretending to be ChromeOS aarch64 *still gets 4K*. Specifically: `Mozilla/5.0 (X11; CrOS aarch64 10452.96.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36` still works.
User Agents should be optional. The whole idea of the Internet was that the server should respond the same way to the same request regardless of the client’s qualities.
You can do language codes in the URL to serve different versions of content
If your browser can do TLS then it should be able to handle gzip content or alternatively if the internet didn’t allow cookies and scripting in your browser then it would have been safe to use TLSs built in compression
Check out the Gemini protocol if you want to see that a lot of HTTP spec stuff is completely unnecessary
But they are useful and completely valid ways of dealing with the problem.
It is not the end of the world if I have to click am extra once or twice to change the language. Hell most websites have much harder processes just to reject cookies.
Personally I would rather err on the side of slightly extra work the odd time I’m not on a website not in my native language than have an extra bit of information that can be used to track me.
Again take a look at the Gemini protocol, its a perfectly fine browsing experience without all the cruft.
Some widely spoken language I imagine, Chinese, Spanish, English I don’t care. Since .com is intended for commercial use, the language of the companies biggest market makes sense here as well.
You’re also forgetting that the likes of google.ru, google.nl and google.every_other_country_code exist.
Also there are plently of websites the have language selection in the site that overrides that header, look at Wikipedia.
There are plently of sites in non english languages that cater to non English speakers only, not every site has or needs 10 different translations.
At this point we also have translation engines in the browser so for pages in languages you don’t know, that you absolutely need to access, you can use it to understand the page to a decent level and/or be able to navigate to a version in your language if available.
I just used it as an example since it’s pretty much the lingua franca of the internet and it’s what we are currently using. The same argument applies to any other language.
My main point with that bit was that a lot of content exists on the internet without any translated versions and the world hasn’t ended because of this, look at non English Lemmy instances.


User Agents should be optional. The whole idea of the Internet was that the server should respond the same way to the same request regardless of the client’s qualities.
There are qualities that are useful for having different responses, like supported language, whether the browser accepts gzipped content, etc.
Fuck that shit.
Check out the Gemini protocol if you want to see that a lot of HTTP spec stuff is completely unnecessary
The issue is that some of those techniques are only useful after the client has rendered the content rather than before.
But they are useful and completely valid ways of dealing with the problem.
It is not the end of the world if I have to click am extra once or twice to change the language. Hell most websites have much harder processes just to reject cookies.
Personally I would rather err on the side of slightly extra work the odd time I’m not on a website not in my native language than have an extra bit of information that can be used to track me.
Again take a look at the Gemini protocol, its a perfectly fine browsing experience without all the cruft.
So if I type in “google.com” what language should the front page be in?
First language in Accept-Language header that server also support
Yeah, User Agent is also a header, which the other guy is saying shouldn’t exist.
Some widely spoken language I imagine, Chinese, Spanish, English I don’t care. Since .com is intended for commercial use, the language of the companies biggest market makes sense here as well.
You’re also forgetting that the likes of google.ru, google.nl and google.every_other_country_code exist.
Also there are plently of websites the have language selection in the site that overrides that header, look at Wikipedia.
There are plently of sites in non english languages that cater to non English speakers only, not every site has or needs 10 different translations.
At this point we also have translation engines in the browser so for pages in languages you don’t know, that you absolutely need to access, you can use it to understand the page to a decent level and/or be able to navigate to a version in your language if available.
Who said anything about English?
I just used it as an example since it’s pretty much the lingua franca of the internet and it’s what we are currently using. The same argument applies to any other language.
My main point with that bit was that a lot of content exists on the internet without any translated versions and the world hasn’t ended because of this, look at non English Lemmy instances.
That’s in separate headers
Bot
Bot